七、数据结构
1.数组
同https://www.youngxy.top/page/Java-SE/二、List.html
2.链表
同https://www.youngxy.top/page/Java-SE/二、List.html
3.栈
同https://www.youngxy.top/page/Java-SE/二、List.html
3.1Java官方推荐的实现方式:Deque
今日在刷LeetCode hot100的时候,看到K神题解下的一个评论:

所以,我一个小白当然是去百度一下这个Deque为啥Java官方要推荐作为Stack的实现呢?
话不多说,直接上菜!
3.1.1Q1:在 Java 语言中,不推荐使用 Stack 类?
是的。实际上,这个不推荐不是某个技术专家或者某个企业的规范标准,而是来自 Java 官方。
如果大家在 Java 中查询 Stack 的文档,就会看到如下标为蓝色的说明:

简单翻译:一个更加完整,一致的,后进先出的栈相关的操作,应该由 Deque 接口提供。并且,也推荐使用 Deque 这种数据结构(比如 ArrayDeque)来实现。
因此,如果你想使用栈这种数据结构,Java 官方推荐的写法是这样的(假设容器中的类型是 Integer):
Deque<Integer> stack = new ArrayDeque<Integer>();
3.1.2Q2:Java 中的 Stack 类到底怎么了?
Java 中的 Stack 类,最大的问题是,继承了 Vector 这个类。根据 Java 官方文档中的类关系,如下所示:

Vector 是什么类?简单来说,Vector 就是一个动态数组。
最大的问题在于,继承使得子类继承了父类的所有公有方法。
而 Vector 作为动态数组,是有能力在数组中的任何位置添加或者删除元素的。因此,Stack 继承了 Vector,Stack 也有这样的能力!
尝试如下的代码片段,在 Java 中是正确的:
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.add(1, 666);
3.1.3Q3:问题出在哪里?
Java 中的 Stack 实现,是被业界一直认为非常糟糕的实现。实际上,它犯了面向对象设计领域的一个基本错误:Stack 和 Vector 之间的关系,不应该是继承关系,而应该是组合关系(composition)。
关于继承关系和组合关系的区别,相信大家在 OOD 学习过程中,听过无数遍。
继承关系描述的是 is-a 的关系,即“是一个”的关系。
猫是一个动物,所以猫这个类可以继承动物类;
程序员是一个雇员,所以程序员这个类可以继承雇员类。
而组合关系描述的是 has-a 的关系,即“有一个”的关系。
车里有一台发动机,所以发动机这个类和车这个类之间,应该是组合关系,即车中包含一个成员变量,是发动机这个类的对象;
电脑里有 CPU,内存,显卡。所以 CPU,内存,显卡,这些类和电脑类之间的关系,都应该是组合关系。
上面这些例子,都是我们在生活中看得到摸得到的实体,我们在做类设计的时候,通常不会犯糊涂。但遇到更抽象的对象的时候,事情可能就不一样了。
比如,栈这种数据结构,和动态数组这种数据结构之间,到底应该是 is-a 的关系?还是 has-a 的关系?
使用自然语言描述,听起来似乎说:栈是一个动态数组,毛病不大。但其实仔细思考,就会发现,栈不是一个动态数组!
因此,很多时候,对于现实中并不存在的设计对象,人类很可能想不清楚 is-a 和 has-a 的关系。在这里,我再提供一个简单的原则:判断一下,如果设计成继承关系的话,我们是否有可能把子类进行向上的父类转型?如果可能,则应该设计成继承关系,否则应该是组合关系。
换句话说,在这个例子中,我们是否可能将栈当做一个动态数组使用?答案是不可能。所以,栈和动态数组之间的关系不应该是继承关系。
实际上,在真实的世界中,真正的继承关系是很少的。真正的继承关系中,父类大多是一个很抽象的概念,比如“人”,比如“动物”。但是我们设计的大多数类,不是这么抽象的概念。整体来说,组成关系更常用。
这个概念不是我说的,而是业界公认的 OOP 设计原则。叫做:Composition over inheritance。如果用中文说,就是应该优先考虑组合关系。
在 OOP 设计中,很多人会更倾向于使用继承关系,毕竟继承关系看起来更“面向对象”一些,也是面向对象讲解的重点。但是,在具体实践中,组合更常见!说得再绝对一些:多用组合,少用继承!
3.1.4Q4:Java 官方不知道这个 Stack 类的实现不好吗?为什么不改?
Java 官方当然知道这个实现不好。但是,因为要保持兼容性(backward compatibility),对于已经正式发布的代码,Java 官方不能做接口设计层面的修改。否则,使用老版本 Java 的程序,将在新的 Java 环境下无法执行,这是 Java 官方不愿意看到的。
Java 官方可以做到的是,将这个类标志成“弃用”(deprecated),以让新版本的开发者不再允许使用这个类,但老版本的程序,还能继续执行。
但是,这么多年了,Java 官方也并没有将 Stack 标为“弃用”,只是在文档上注明“不建议使用”。
3.1.5Q5:为什么使用接口?
下面,我们再来看一下 Java 官方推荐的写法:使用 Deque 接口:
Deque<Integer> stack = new ArrayDeque<Integer>();
接口最大的意义之一,就是做了更高层次的抽象:只定义了一个类应该满足哪些方法,而对具体的实现方式不做限制。
比如,我们都知道,在 Java 语言中,Queue 就是一个接口。我们想实现一个队列,可以这么写:
Queue<Integer> q1 = new ArrayDeque<>();
Queue<Integer> q2 = new LinkedList<>();
在上述实现中,q1 和 q2 的底层具体实现不同,一个是 LinkedList,一个是 ArrayDeque。但是,从用户的角度看,q1 和 q2 是一致的:都是一个队列,只能执行队列规定的方法。
这样做,将“队列”这样一个概念,和底层数据结构的具体实现——LinkedList 或者 ArrayDeque 解耦了:
底层开发人员可以随意维护自己的 LinkedList 类或者 ArrayDeque 类,只要他们满足 Queue 接口规定的规范;
开发者可以选择合适的数据结构来定义 Queue;
而 Queue 的更上层使用者,无需知道 q1 或者 q2 的实现细节,从他们的角度看,只要能调用 Queue 的相关方法:peek, poll, offer 等等,来满足上层的业务需求,就好了。
而且这样做,完美解决了之前说的,继承关系把父类的所有方法都拿过来的问题。接口的设计相当于做了访问限制。LinkedList 中有很多方法,但是,当我们使用 LinkedList 实现 Queue 接口的时候,用户只能调用 Queue 中定义的方法。
从这个角度,我们也能看出 Stack 设计的另一个不合理之处:Stack 和 Queue 同样作为一种特殊的线性数据结构,都应该只是规定一系列操作的接口而已,具体的底层实现,由开发者再做选择。
但因为 Stack 做成了一个类,继承了 Vector,也就只能基于 Vector 这一种固定的数据结构了。
为了修正这个问题,Java 官方推出了 Deque 接口,作为实现栈的接口。
3.1.6Q6:什么是 Deque 接口?
Deque 是双端队列的意思。所谓的双端队列,就是能在线性数据结构的两段,进行插入和删除操作。
大家可以想象,由于 Stack 的定义是在同一端进,同一端出。所以,如果 Deque 可以满足在两段进行插入和删除,自然也能在同一端进行插入和删除,也就是可以以此为基础,做成一个 Stack。
3.1.7Q7:等等!这里有问题!
很多同学应该能马上反应过来了。这里有问题!
因为我们根据 Java 官方推荐的方法声明的这个 Stack,虽然变量名称是Stack,但它实际上是一个 Deque。这就意味着,这个Stack,可以在两段做插入和删除操作!但是,真正的栈,只能在同一端做插入和删除操作!
这难道不是重蹈了 Stack 这个类的覆辙?毕竟,我们最开始分析,就说 Stack 这个类的一大问题,是继承了 Vector 这个类的若干我们不需要的方法,破坏了封装性,比如在任何一个位置插入一个元素。现在这个基于 Deque 接口的Stack,依然有我们不需要的方法啊!
没错!这就是 Java 的历史遗留问题了。这个问题至此已经无解了。因为 Stack 这个关键字被占据了。Java 官方不想推出一个叫做 RealStack 或者 CorrectStack 一类的接口名称。所以,按照 Java 官方的推荐所建立的这个Stack,依然不完美。
但至今为止,Java 暂时只是做到这个份儿上。
或许,Oracle 少打一些官司,多研究一下如何处理这些历史遗留问题,Java 能更好吧。
所以,在实际的工程应用上,有人也并不建议使用 Deque 做为 Stack 的实现,而是自己再做一层封装。
比如,大家可以看一下这篇探讨 Stack 和 Deque 的文章:http://baddotrobot.com/blog/2013/01/10/stack-vs-deque/。

3.1.8Q8:链表呢?
再说一个小问题。
大家可以看到,Java 官方推荐的创建栈的方式,使用了 Deque 接口。并且,在底层实现上,使用了 ArrayDeque,也就是基于动态数组的实现。为什么?
大家应该都知道,动态数组是可以进行扩容操作的。在触发扩容的时候,时间复杂度是 O(n) 的,但整体平均时间复杂度(Amortized Time)是 O(1)。
但是,基于链表的实现,不会牵扯到扩容问题,因此,每一次添加操作,从时间复杂度的角度,都是 O(1) 的。
虽然如此,可是实际上,当数据量达到一定程度的时候,链表的性能是远远低于动态数组的。
这是因为,对于链表来说,每添加一个元素,都需要重新创建一个 Node 类的对象,也就是都需要进行一次 new 的内存操作。而对内存的操作,是非常慢的。
举个例子,对于队列,测试它们的性能。代码如下:
Queue<Integer> q1 = new ArrayDeque<>();
Queue<Integer> q2 = new LinkedList<>();
int N = 10000000;
long start1 = System.currentTimeMillis();
for (int i = 0; i < N; i++) {
q1.offer(1);
}
long end1 = System.currentTimeMillis();
long start2 = System.currentTimeMillis();
for (int i = 0; i < N; i++) {
q2.offer(i);
}
long end2 = System.currentTimeMillis();
System.out.println(end1 - start1 + "ms");
System.out.println(end2 - start2 + "ms");
最终的结果:
76ms
4163ms
也就是使用 LinkedList,会比使用 ArrayDeque 慢 5 倍以上!
因此,甚至有人建议:在实践中,尤其是面对大规模数据的时候,不应该使用链表!
最后,关于在面试中,如果有同学需要使用“栈”这种数据结构,选择 Stack 这个类,面试官会怎么看?我参考了网上的其博主的文章写的@lk 同学的看法:
参考:https://blog.csdn.net/Dlgdlgd/article/details/125768706
4.队列
同https://www.youngxy.top/page/Java-SE/二、List.html
5.二叉树
5.1树的定义
定义:树(Tree)是n(n>=0)个结点的有限集T,T为空时称为空树,否则它满足如下两个条件:
- (1)有且仅有一个特定的称为根(Root)的结点;
- (2)其余的结点可分为m(m>=0)个互不相交的子集T1,T2,T3…Tm,其中每个子集又是一棵树,并称其为子树(Subtree)。
要求子树都非空,使子树的个数(和树的结构)能有明确定义:
- 结点个数为0 的树称为空树
- 一棵树可以只有根但没有子树(m = 0),这是一棵单结点的树, 只包含一个根结点
树是一种层次性结构:
- 子树的根看作是树根的下一层元素
- 一棵树里的元素可以根据这种关系分为一层层的元素
一棵树(除树根外)可能有多棵子树,根据是否认为子树的排列顺序有意义,可以把树分为有序树和无序树两种概念。例如,普通的树一般是无序的,二叉搜索树BST是有序的。
5.2树的基本术语
父结点和子结点(是相对定义的):
- 一棵树的根结点称为该树的子树的根结点的父结点
- 子树的根是树根的子结点
边:从父结点到子结点的连线(注意,边有方向)
兄弟结点:父结点相同的结点互为兄弟结点
树叶、分支结点:没有子结点的结点称为树叶,树中的其余结点称为分支结点(注意:分支结点可以只有一个分支)
祖先和子孙:基于父结点/子结点关系和传递性,可以确定相应的传递 关系,称为祖先关系或子孙关系。由这两个关系决定了一个结点的祖先结点,或子孙结点
度数:一个结点的子结点个数称为该结点的度数,显然树叶的度数为0 一棵树的度数就是它里面度数最大的结点的度数
路径,路径长度:
- 从一个祖先结点到其子孙结点的一系列边称为树中一条路径。显然,从一棵树的根到树中任一个结点都有路径,且路径唯一
- 路径中边的条数称为路径长度,认为每个结点到自身有长0 的路径
结点的层数:
- 树根到结点的路径长度是该结点的层数
- 结点都有层数,根所在的层为0
高度(或深度):
- 树的高度或深度是树中结点的最大层数(最长路径的长度)加1
- 是树的整体性质,空树高度为0,只有根结点的树高度为1
5.3二叉树的定义
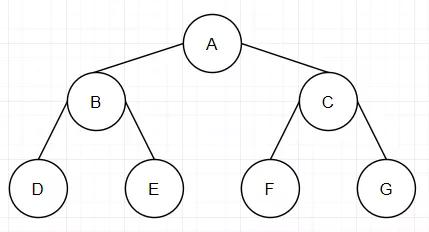
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”和“右子树”。
5.4二叉树的性质
性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>=1)。
性质2:深度为k的二叉树至多有2^k-1个结点(k>=1)。
性质3: 对任何一棵二叉树,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。
性质4:具有n个结点的完全二叉树的深度为[log2n]+1。
性质5: 如果对一棵有n个结点的完全二叉树的结点按层序编号(从第1层到第【log2n】+1层,每层从左到右),则对任一结点i(1<=i<=n),有:
- (1)如果i=1,则结点i无双亲,是二叉树的根;如果i>1,则其双亲是结点【i/2】。
- (2)如果2i>n,则结点i为叶子结点,无左孩子;否则,其左孩子是结点2i。
- (3)如果2i+1>n,则结点i无右孩子;否则,其右孩子是结点2i+1。
5.5二叉树计算
方法:https://blog.csdn.net/yang13563758128/article/details/85109687?spm=1001.2014.3001.5502
6.红黑树
6.1简介
红黑树是一种自平衡的二叉查找树,是一种高效的查找树。红黑树具有良好的效率,它可在 O(logN) 时间内完成查找、增加、删除等操作。
6.2为什么需要红黑树?
对于二叉搜索树,如果插入的数据是随机的,那么它就是接近平衡的二叉树,平衡的二叉树,它的操作效率(查询,插入,删除)效率较高,时间复杂度是O(logN)。但是可能会出现一种极端的情况,那就是插入的数据是有序的(递增或者递减),那么所有的节点都会在根节点的右侧或左侧,此时,二叉搜索树就变为了一个链表,它的操作效率就降低了,时间复杂度为O(N),所以可以认为二叉搜索树的时间复杂度介于O(logN)和O(N)之间,视情况而定。那么为了应对这种极端情况,红黑树就出现了,它是具备了某些特性的二叉搜索树,能解决非平衡树问题,红黑树是一种接近平衡的二叉树(说它是接近平衡因为它并没有像AVL树的平衡因子的概念,它只是靠着满足红黑节点的5条性质来维持一种接近平衡的结构,进而提升整体的性能,并没有严格的卡定某个平衡因子来维持绝对平衡)。
6.3红黑树的特性
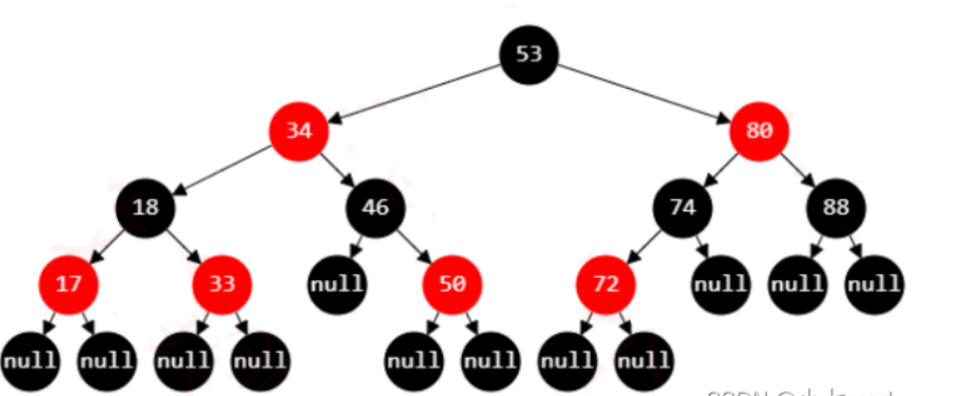
首先,红黑树是一个二叉搜索树,它在每个节点增加了一个存储位记录节点的颜色,可以是RED,也可以是BLACK;通过任意一条从根到叶子简单路径上颜色的约束,红黑树保证最长路径不超过最短路径的二倍,因而近似平衡(最短路径就是全黑节点,最长路径就是一个红节点一个黑节点,当从根节点到叶子节点的路径上黑色节点相同时,最长路径刚好是最短路径的两倍)。它同时满足以下特性:
节点是红色或黑色
根是黑色
叶子节点(外部节点,空节点)都是**黑色,**这里的叶子节点指的是最底层的空节点(外部节点),下图中的那些null节点才是叶子节点,null节点的父节点在红黑树里不将其看作叶子节点
红色节点的子节点都是黑色;
红色节点的父节点都是黑色;
从根节点到叶子节点的所有路径上不能有 2 个连续的红色节点
从任一节点到叶子节点的所有路径都包含相同数目的黑色节点
6.4红黑树的效率
红黑树的查找,插入和删除操作,时间复杂度都是O(logN)。
查找操作时,它和普通的相对平衡的二叉搜索树的效率相同,都是通过相同的方式来查找的,没有用到红黑树特有的特性。
但如果插入的时候是有序数据,那么红黑树的查询效率就比二叉搜索树要高了,因为此时二叉搜索树不是平衡树,它的时间复杂度O(N)。
插入和删除操作时,由于红黑树的每次操作平均要旋转一次和变换颜色,所以它比普通的二叉搜索树效率要低一点,不过时间复杂度仍然是O(logN)。总之,红黑树的优点就是对有序数据的查询操作不会慢到O(N)的时间复杂度。
红黑树和AVL树的比较:
- AVL树的时间复杂度虽然优于红黑树,但是对于现在的计算机,cpu太快,可以忽略性能差异
- 红黑树的插入删除比AVL树更便于控制操作
- 红黑树整体性能略优于AVL树(红黑树旋转情况少于AVL树)