来看头条
1.项目介绍
开发技术:Spring Cloud + Spring Boot + MybatisPlus + Redis + MySQL + Mongodb + Zookeeper + kafka + ElasticSearch + Docker + 第三方技术阿里云OSS;
项目背景:”来看头条“ 项目类似于今日头条,是一个新闻资讯类项目。该项目由用户端和自媒体端组成。在用户端,实现了用户通过app端登录功能、浏览文章功能、搜索文章功能、用户历史记录功能。在自媒体端,实现了自媒体管理员登录功能、发布文章功能、删除文章功能、上传素材功能、文章内容审核功能
项目重难点: 网关搭建;文章详情静态化及存储;文章自动审核及延迟发布;分布式锁解决集群下的方法抢占执行;热点文章实时计算
技术栈的具体应用:
- Spring-Cloud-Gateway : 微服务之前架设的网关服务,实现服务注册中的API请求路由,以及控制流速控制和熔断处理都是常用的架构手段,而这些功能Gateway天然支持
- 运用Spring Boot快速开发框架,构建项目工程;并结合Spring Cloud全家桶技术,实现app后端、自媒体等微服务。
- 运用Spring Cloud Alibaba Nacos作为项目中的注册中心和配置中心
- 运用mybatis-plus作为持久层提升开发效率
- 采用kafka作为消息服务中间件,把自媒体文章上下架放进消息队列;通过用户的行为(点赞、评论、喜欢)实时记录用户数据,通过kafkaStream流式计算最新的数据;与客户端系统消息通知
- 运用Redis缓存技术,实现热数据的计算,提升系统性能指标,同时作为消息中间件异步消费任务。
- 使用Mysql存储用户数据,以保证数据查询的高性能
- 使用Mongodb存储用户历史记录数据,以保证用户热数据高扩展和高性能指标
- 运用AI技术,来完成系统自动化功能,以提升效率及节省成本,比如文章审核
2.优化
2.1优化一
**缺陷 :**写操作(定时刷新)比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。
解决办法:
- 数据库和缓存数据强一致场景 :更新 db 的时候同样更新 cache,不过我们需要加一个分布式锁来保证更新 cache 的时候不存在线程安全问题。
2.2优化二
**缺陷:**消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法:
- 我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
- 解决Kafka重复消费,开启kafka本身存在的幂等性。acks=all和enable.idempotence=true来保证幂等性,这样 Producer 在重试发送消息时,Broker端就可以过滤重复消息。
2.3优化三
2.3.1存储技术选型:
| 功能 | 阿里云oss | minio |
|---|---|---|
| 文件管理 | √ | √ |
| 文件管理权限策略 | √ | √ |
| 纠删码数据修复 | √ | √ |
| 持续备份 | √ | √ |
| 使用SDK管理资源 | √ | √ |
| 监控 | √ | √ |
| 版本控制 | 开启版本控制后,针对文件的覆盖和删除操作将会以历史版本的形式保存下来,在错误覆盖或者删除文件后,能够将存储空间中存储的文件恢复至任意时刻的历史版本 | × |
| 在指定时间内自动批量删除 | 支持生命周期规则,您可以通过生命周期规则定期将非热门数据转换为低频访问、归档存储或冷归档存储,并删除过期数据 | × |
| 提升数据上传、下载速率 | 支持传输加速服务 | 受限于服务器网卡带宽 |
| 高性能、高吞吐的数据访问服务 | 缓存OSS中的热点文件,并提供高性能、高吞吐量的数据访问服务 | 设置访问一个对象并下载下来进行缓存,那接下来的请求都会直接访问缓存磁盘上的对象,直至其过期失效 |
| 加密、保护敏感数据 | √ | × |
| 防护DDoS攻击 | 当受保护的Bucket遭受大流量攻击时,OSS高防会将攻击流量牵引至高防集群进行清洗,并将正常访问流量回源到目标Bucket,确保业务的正常进行。 | × |
| 记录资源的访问信息 | 可以通过日志功能完成OSS的操作审计、访问统计、异常事件回溯和问题定位等工作 | × |
| 控制流量 | 在上传、下载、拷贝文件时进行流量控制,以保证您其他应用的网络带宽 | × |
| 对数据进行分析和处理 | 图片处理、视频截帧、智能媒体管理 | × |
| 使用工具管理资源 | OSS支持图形化工具、命令行工具、文件挂载工具、FTP工具等方便您管理OSS资源 | 支持图形化工具、命令行工、各类SDK |
| 同城容灾、异地容灾 | √ | × |
| 数据合规保留 | 允许用户以“不可删除、不可篡改”方式保存和使用数据。 | × |
阿里云OSS是一个成熟的云服务,由阿里云提供技术支持和服务保障,使用方便,与其他阿里云服务集成度高。MinIO是开源软件,需要自行部署和维护。OSS有成熟的访问权限控制,安全性好。MinIO安全性取决于自行配置。
2.3.2数据库框架选型:
MyBatis和MyBatis-Plus都是Java语言中非常常用的ORM框架,二者有以下区别:
实现方式不同:
MyBatis是基于XML或注解方式进行数据库操作的持久化框架,它提供了简单的CRUD操作及动态SQL生成等功能。而MyBatis-Plus是在MyBatis框架上的封装,通过对于增强简化后的API更加方便地进行开发,并且在性能、效率和易用性上都有一定的优化。
编程风格有所差异:
MyBatis的编程风格更加传统,需要定义mapper.xml文件并根据传入的参数使用相应的SQL查询语句,需要实现 Mybatis 提供的各种方法;而MyBatis-Plus具有许多针对CRUD进行的简化方法,通过继承BaseMapper以及使用Lambda表达式,可以让我们像SpringDataJPA类似地使用接口编程方式进行数据库操作。
下面通过代码示例来演示一下MyBatis和MyBatis-Plus的区别:
- MyBatis的实现
首先在Mybatis中需要配置sql mapper映射文件,如下所示:
<!-- userMapper.xml -->
<mapper namespace="com.demo.dao.UserMapper">
<select id="getUserById" parameterType="java.lang.Integer" resultType="com.demo.entity.User">
select * from t_user where id=#{id}
</select>
</mapper>
然后通过Mybatis的SqlSession执行相关方法实现数据查询:
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(configuration);
SqlSession sqlSession = sessionFactory.openSession();
User user = sqlSession.selectOne("com.demo.dao.UserMapper.getUserById", 1);
sqlSession.close();
- MyBatis-Plus的实现
在MyBatis-Plus中则要比上述方式简单得多,并且提供了更加方便的CRUD操作。例如我们可以定义一个接口继承BaseMapper接口并调用其中提供的方法来操作数据库,如下所示:
public interface UserMapper extends BaseMapper<User> {
}
以下是从数据库中根据ID查询数据时,可以在Service层直接调用BaseMapper中提供的selectById()方法:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Override
public User getUserById(Long id) {
return baseMapper.selectById(id);
}
}
参考:https://blog.csdn.net/qq_51447496/article/details/131166800
2.3.3消息队列选型:
详细请参考:https://www.youngxy.top/page/Kafka/Kafka.html
Kafka 和 RocketMQ 都支持 10w 级别的高吞吐量。
Kafka 一开始的目的就是用于日志收集和传输,适合有大量数据产生的互联网业务,特别是大数据领域的实时计算、日志采集等场景,用 Kafka 绝对没错,社区活跃度高,业内标准。
RocketMQ 特别适用于金融互联网领域这类对于可靠性要求很高的场景,比如订单交易等,而且 RocketMQ 是阿里出品的,经历过那么多次淘宝双十一的考验,大品牌,在稳定性值得信赖。但如果阿里不再维护这个技术了,社区有可能突然黄掉的风险。因此如果公司对自己的技术实力有自信,基础架构研发实力较强,推荐用 RocketMQ。
RabbitMQ 适用于公司对外提供能力,可能会有很多主题接入的中台业务场景,毕竟它是百万级主题数的。它的时效性是毫秒级的,但实际毫秒级和微秒级在感知上没有什么太大的区别,所以它的这一大优点并不太会作为考量标准。同时,它的功能是比较完善的,开源社区活跃度高,能解决开发中遇到的bug,所以万级别数据量业务场景的小公司可以优先选择功能完善的RabbitMQ。它的缺点就是用 Erlang 语言编写,所以很多开发人员很难去看懂源码并进行二次开发和维护,也就是说对于公司来说可能处于不可控的状态。
ActiveMQ 现在很少有人用,没怎么经过大规模吞吐量场景的考验,社区不怎么活跃,官方社区现在对 ActiveMQ 5.x 维护也越来越少,所以不推荐使用。
消息中间件对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 100万级 |
| 时效性 | ms | us | ms | ms级以内 |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 功能特性 | 成熟的产品、较全的文档、各种协议支持好 | 并发能力强、性能好、延迟低 | MQ功能比较完善,扩展性佳 | 只支持主要的MQ功能,主要应用于大数据领域 |
消息中间件对比-选择建议
| 消息中间件 | 建议 |
|---|---|
| Kafka | 追求高吞吐量,适合产生大量数据的互联网服务的数据收集业务 |
| RocketMQ | 可靠性要求很高的金融互联网领域,稳定性高,经历了多次阿里双11考验 |
| RabbitMQ | 性能较好,社区活跃度高,数据量没有那么大,优先选择功能比较完备的RabbitMQ |
2.4优化四
缺陷:对于变量存在多线程并发竞争
解决办法:
为变量设置ThreadLocal。
2.5身份验证怎么做的?
AuthorizedFilter + AppJwtUtil
- 用户向服务器发送用户名、密码以及验证码用于登陆系统。用户进入网关开始登陆,网关过滤器进行判断,如果是登录,则路由到后台管理微服务进行登录。
- 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT。
- 用户以后每次向后端发请求都在 Header 中带上这个 JWT ,再次进入网关开始访问,网关过滤器接收用户携带的TOKEN。
- 服务端检查 JWT 并从中获取用户相关信息。网关过滤器解析TOKEN ,判断是否有权限,如果有,则放行,如果没有则返回未认证错误。
两点建议:
- 建议将 JWT 存放在 localStorage 中,放在 Cookie 中会有 CSRF 风险。
- 请求服务端并携带 JWT 的常见做法是将其放在 HTTP Header 的
Authorization字段中(Authorization: Bearer Token)。
乐观锁:
使用版本号。
分布式id:
随着业务的增长,文章表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
文章端相关的表都使用雪花算法生成id,包括ap_article、 ap_article_config、 ap_article_content
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
第一:在实体类中的id上加入如下配置,指定类型为id_worker
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
第二:在application.yml文件中配置数据中心id和机器id
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.article.pojos
global-config:
datacenter-id: 1
workerId: 1
2.6网关搭建:
思路分析:
- 用户进入网关开始登陆,网关过滤器进行判断,如果是登录,则路由到后台管理微服务进行登录
- 用户登录成功,后台管理微服务签发JWT TOKEN信息返回给用户
- 用户再次进入网关开始访问,网关过滤器接收用户携带的TOKEN
- 网关过滤器解析TOKEN ,判断是否有权限,如果有,则放行,如果没有则返回未认证错误
具体实现:
第一:
在认证过滤器中需要用到jwt的解析,所以需要把工具类拷贝一份到网关微服务
第二:
在网关微服务中新建全局过滤器
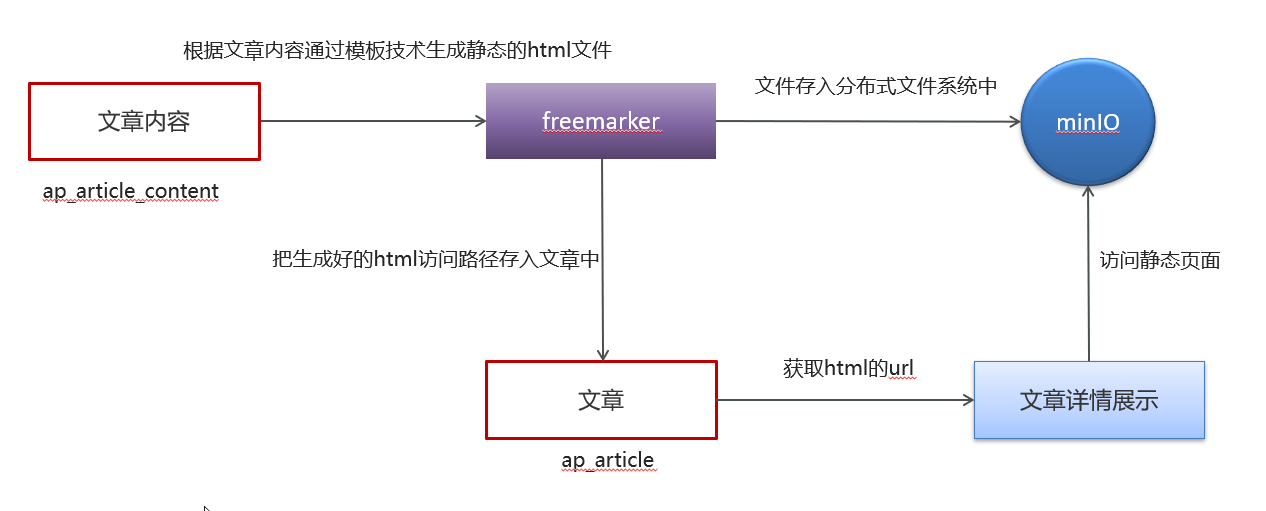
2.7文章详情静态化及存储:
文章详情静态化:
FreeMarker 是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。 它不是面向最终用户的,而是一个Java类库,是一款程序员可以嵌入他们所开发产品的组件。
模板编写为FreeMarker Template Language (FTL)。它是简单的,专用的语言, 不是像PHP那样成熟的编程语言。 那就意味着要准备数据在真实编程语言中来显示,比如数据库查询和业务运算, 之后模板显示已经准备好的数据。在模板中,你可以专注于如何展现数据, 而在模板之外可以专注于要展示什么数据。
存储:AliyunOSS
对象存储可提供更好的数据保护,加密、保护敏感数据。
2.8文章自动审核及延迟发布:
文章自动审核:
1 自媒体端发布文章后,开始审核文章(异步线程的方式审核文章,在自动审核的方法上加上@Async注解(标明要异步调用),在自媒体引导类中使用@EnableAsync注解开启异步调用)
2 审核的主要是审核文章的内容(文本内容和图片)
3 借助第三方提供的接口审核文本
4 借助第三方提供的接口审核图片,由于图片存储到OSS中,需要先下载才能审核
5 如果审核失败,则需要修改自媒体文章的状态,status:2 审核失败 status:3 转到人工审核
6 如果审核成功,则需要在文章微服务中创建app端需要的文章:
在文章审核成功以后需要在app的article库中新增文章数据:
保存文章信息 ap_article
保存文章配置信息 ap_article_config
保存文章内容 ap_article_content
WmNewsAutoScanServiceImpl:
package com.xy.wemedia.service.impl;
import com.alibaba.fastjson.JSONArray;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.xy.common.aliyun.GreenImageScan;
import com.xy.common.aliyun.GreenTextScan;
import com.xy.common.aliyun.ImageScan;
import com.xy.common.aliyun.TextScan;
import com.xy.common.tess4j.Tess4jClient;
import com.xy.file.service.FileStorageService;
import com.xy.model.article.dtos.ArticleDto;
import com.xy.model.common.dtos.ResponseResult;
import com.xy.model.wemedia.pojos.WmChannel;
import com.xy.model.wemedia.pojos.WmNews;
import com.xy.model.wemedia.pojos.WmSensitive;
import com.xy.model.wemedia.pojos.WmUser;
import com.xy.utils.common.SensitiveWordUtil;
import com.xy.wemedia.mapper.WmChannelMapper;
import com.xy.wemedia.mapper.WmNewsMapper;
import com.xy.wemedia.mapper.WmSensitiveMapper;
import com.xy.wemedia.mapper.WmUserMapper;
import com.xy.wemedia.service.WmNewsAutoScanService;
import com.xy.apis.article.IArticleClient;
import lombok.extern.slf4j.Slf4j;
import net.sourceforge.tess4j.TesseractException;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.*;
import java.util.stream.Collectors;
/**
* @author 杨路恒
*/
@Service
//@Transactional
@Slf4j
public class WmNewsAutoScanServiceImpl implements WmNewsAutoScanService {
@Autowired
private WmNewsMapper wmNewsMapper;
/**
* 自媒体文章审核
* @param id 自媒体文章id
*/
@Override
@Async //标明当前方法是一个异步方法
public void autoScanWmNews(Integer id) {
//1.查询自媒体文章
WmNews wmNews = wmNewsMapper.selectById(id);
if (wmNews == null){
throw new RuntimeException("WmNewsAutoScanServiceImpl-文章不存在");
}
if (wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())){
//从内容中提取纯文本内容和图片
Map<String,Object> textAndImages = handleTextAndImages(wmNews);
//自管理的敏感词过滤
boolean isSensitive = handleSensitiveScan((String) textAndImages.get("content"), wmNews);
if(!isSensitive){
return;
}
//2.审核文本内容 阿里云接口
boolean isTextScan = handleTextScan((String) textAndImages.get("content"),wmNews);
if (!isTextScan){
return;
}
//3.审核图片 阿里云接口
boolean isImageScan = handleImageScan((List<String>) textAndImages.get("images"),wmNews);
// isImageScan = true;
if (!isImageScan){
return;
}
//4.审核成功,保存app端的相关的文章数据
ResponseResult responseResult = saveAppArticle(wmNews);
if(!responseResult.getCode().equals(200)){
throw new RuntimeException("WmNewsAutoScanServiceImpl-文章审核,保存app端相关文章数据失败");
}
//回填article_id
wmNews.setArticleId((Long) responseResult.getData());
updateWmNews(wmNews,(short) 9,"审核成功");
// saveAppArticle(wmNews);
}
}
@Autowired
private WmSensitiveMapper wmSensitiveMapper;
/**
* 自管理的敏感词审核
* @param content
* @param wmNews
* @return
*/
private boolean handleSensitiveScan(String content, WmNews wmNews) {
boolean flag =true;
//获取所有的敏感词
List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));
List<String> sensitiveList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());
//初始化敏感词库
SensitiveWordUtil.initMap(sensitiveList);
//查看文章中是否包含敏感词
Map<String, Integer> map = SensitiveWordUtil.matchWords(content);
if (map.size() > 0){
updateWmNews(wmNews, (short) 2,"当前文章中存在违规内容" + map);
flag = false;
}
return flag;
}
@Autowired
private IArticleClient iArticleClient;
@Autowired
private WmChannelMapper wmChannelMapper;
@Autowired
private WmUserMapper wmUserMapper;
/**
* 修改文章内容
* @param wmNews
* @param i
* @param reason
*/
private void updateWmNews(WmNews wmNews, short i, String reason) {
wmNews.setStatus(i);
wmNews.setReason(reason);
wmNewsMapper.updateById(wmNews);
}
/**
* 保存app端相关的文章数据
* @param wmNews
* @return
*/
private ResponseResult saveAppArticle(WmNews wmNews) {
ArticleDto articleDto = new ArticleDto();
//属性的拷贝
BeanUtils.copyProperties(wmNews,articleDto);
//文章的布局
articleDto.setLayout(wmNews.getType());
//频道
WmChannel wmChannel = wmChannelMapper.selectById(wmNews.getChannelId());
if (wmChannel != null){
articleDto.setChannelName(wmChannel.getName());
}
//作者
articleDto.setAuthorId(wmNews.getUserId().longValue());
WmUser wmUser = wmUserMapper.selectById(wmNews.getUserId());
if (wmUser != null){
articleDto.setAuthorName(wmUser.getName());
}
//设置文章id
if (wmNews.getArticleId() != null){
articleDto.setId(wmNews.getArticleId());
}
articleDto.setCreatedTime(new Date());
System.out.println(articleDto.getId());
ResponseResult responseResult = iArticleClient.saveArticle(articleDto);
return responseResult;
}
@Autowired
private FileStorageService fileStorageService;
@Autowired
private GreenImageScan greenImageScan;
@Autowired
private Tess4jClient tess4jClient;
@Autowired
private ImageScan imageScan;
/**
* 审核图片
* @param images
* @param wmNews
* @return
*/
private boolean handleImageScan(List<String> images, WmNews wmNews) {
boolean flag = true;
if (images == null || images.size() == 0){
return flag;
}
//下载图片 minIO
//图片去重
images = images.stream().distinct().collect(Collectors.toList());
// List<byte[]> imageList = new ArrayList<byte[]>();
// try {
// for (String image : images) {
// byte[] bytes = fileStorageService.downLoadFile(image);
// ByteArrayInputStream in = new ByteArrayInputStream(bytes);
// BufferedImage imageFile = ImageIO.read(in);
// String result = tess4jClient.doOCR(imageFile);
// boolean isSensitive = handleSensitiveScan(result, wmNews);
// if (!isSensitive){
// return isSensitive;
// }
// imageList.add(bytes);
// }
// } catch (Exception e) {
// e.printStackTrace();
// }
List<String> imageList = images;
//审核图片
try {
// Map map = greenImageScan.imageScan(imageList);
Map map = imageScan.imageScan(imageList);
if (map != null){
//审核失败
if(map.get("suggestion").equals("block")){
flag = false;
updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容");
}
//不确定信息 需要人工审核
else if (map.get("suggestion").equals("review")){
flag = false;
updateWmNews(wmNews, (short)3,"当前文章中存在不确定内容");
}
}
} catch (Exception e) {
flag = false;
e.printStackTrace();
}
return flag;
}
@Autowired
private GreenTextScan greenTextScan;
@Autowired
private TextScan textScan;
/**
* 审核纯文本内容
* @param content
* @param wmNews
* @return
*/
private boolean handleTextScan(String content, WmNews wmNews) {
boolean flag = true;
if ((wmNews.getTitle() + "-" + content).length() == 0){
return flag;
}
try {
Map map = textScan.greenTextScan(wmNews.getTitle() + "-" + content);
if (map != null){
//审核失败
if(map.get("suggestion").equals("block")){
flag = false;
updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容");
}
//不确定信息 需要人工审核
else if (map.get("suggestion").equals("review")){
flag = false;
updateWmNews(wmNews, (short)3,"当前文章中存在不确定内容");
}
}
} catch (Exception e) {
flag = false;
e.printStackTrace();
}
return flag;
}
/**
* 1.从自媒体文章的内容中提取文本和图片
* 2.提取文章的封面图片
* @param wmNews
* @return
*/
private Map<String, Object> handleTextAndImages(WmNews wmNews) {
//存储纯文本内容
StringBuilder stringBuilder = new StringBuilder();
List<String> images = new ArrayList<>();
//1.从自媒体文章的内容中提取文本和图片
if (StringUtils.isNoneBlank(wmNews.getContent())){
List<Map> maps = JSONArray.parseArray(wmNews.getContent(), Map.class);
for (Map map : maps) {
if (map.get("type").equals("text")){
stringBuilder.append(map.get("value"));
}
if (map.get("type").equals("images")){
images.add((String) map.get("value"));
}
}
}
//2.提取文章的封面图片
if (StringUtils.isNoneBlank(wmNews.getImages())){
String[] split = wmNews.getImages().split(",");
images.addAll(Arrays.asList(split));
}
Map<String,Object> resultMap = new HashMap<>();
resultMap.put("content",stringBuilder.toString());
resultMap.put("images",images);
return resultMap;
}
}
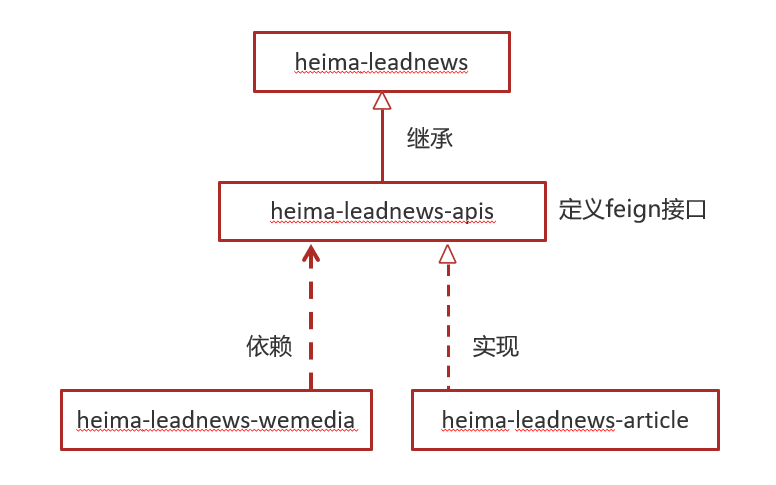
在heima-leadnews-wemedia服务中已经依赖了heima-leadnews-feign-apis工程,只需要在自媒体的引导类中开启feign的远程调用即可
注解为:@EnableFeignClients(basePackages = "com.heima.apis") 需要指向apis这个包。
package com.xy.wemedia;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
import org.springframework.context.annotation.Bean;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
/**
* @author 杨路恒
*/
@SpringBootApplication
@EnableDiscoveryClient
@MapperScan("com.xy.wemedia.mapper")
@EnableFeignClients(basePackages = "com.xy.apis")
@EnableAsync //开启异步调用
@EnableScheduling //开启调度任务
public class WemediaApplication {
public static void main(String[] args) {
SpringApplication.run(WemediaApplication.class,args);
}
/**
* 分页拦截器
* @return
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
延迟发布:
有几个可能的原因项目中使用Redis而不是Kafka来实现延迟任务:
- 简单性。Redis相对于Kafka来说更简单,只需要一个Redis实例就可以实现延迟队列,而Kafka需要集群环境。Redis用起来更简单直接。
- 性能需求。如果项目对延迟任务的吞吐量要求不是很高,Redis完全可以满足需要。而Kafka更适合大吞吐量的场景。
- 资源消耗。Redis的资源消耗比较低,部署和运维成本较低。 Kafka的集群环境对资源要求较高。
- 已有Redis。如果项目已经使用了Redis,那么直接复用就可以实现延迟队列,无需引入额外的组件。
- 其他依赖。项目可能已经依赖了Redis的其他功能,比如缓存,消息等。那么直接复用Redis更加方便。
redis实现:zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序。
实现思路:
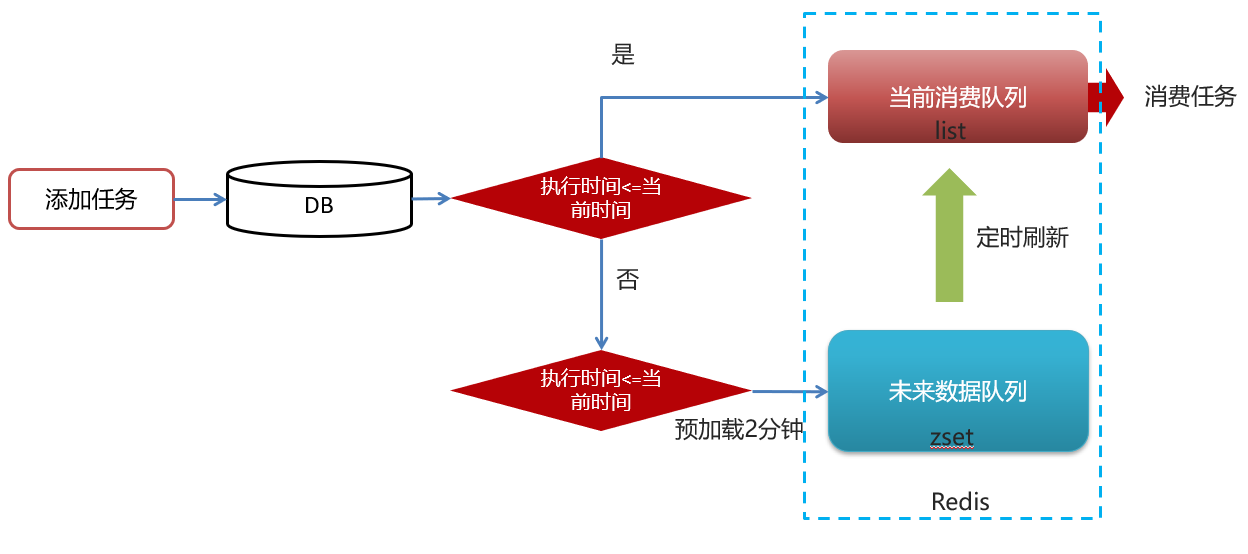
问题思路:
1.为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑。
2.为什么redis中使用两种数据类型,list和zset?
效率问题,算法的时间复杂度
3.在添加zset数据的时候,为什么不需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题,如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可。
实现:
- 延迟队列服务提供对外接口:提供远程的feign接口
- 发布文章集成添加延迟队列接口
- 修改发布文章代码:把之前的异步调用修改为调用延迟任务
- 消费任务进行审核文章
4.为什么选用redis作为消息队列?
把 Redis 当作队列来使用时,会面临的 2 个问题:
- Redis 本身可能会丢数据;
- 面对消息挤压,内存资源会紧张;
所以,能不能将 Redis 作为消息队列来使用,关键看你的业务场景:
如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。
5.未来数据定时刷新
方案1:keys 模糊匹配
keys的模糊匹配功能很方便也很强大,但是在生产环境需要慎用!开发中使用keys的模糊匹配却发现redis的CPU使用率极高,所以公司的redis生产环境将keys命令禁用了!redis是单线程,会被堵塞。
方案2:scan
SCAN 命令是一个基于游标的迭代器,SCAN命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。
在TaskServiceImpl中添加方法:
/**
* 未来数据定时刷新
*/
@Scheduled(cron = "0 */1 * * * ?")
@Override
public void refresh() {
String token = cacheService.tryLock("FUTURE_TASK_SYNC", 1000 * 30);
if (StringUtils.isNotBlank(token)){
log.info("未来数据定时刷新---定时任务");
// 获取所有未来数据集合的key值
Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*");
for (String futureKey : futureKeys) {
String topicKey = ScheduleConstants.TOPIC + futureKey.split(ScheduleConstants.FUTURE)[1];
//获取该组key下当前需要消费的任务数据
Set<String> tasks = cacheService.zRangeByScore(futureKey, 0, System.currentTimeMillis());
if (!tasks.isEmpty()) {
//将这些任务数据添加到消费者队列中
cacheService.refreshWithPipeline(futureKey,topicKey,tasks);
System.out.println("成功的将" + futureKey + "下的当前需要执行的任务数据刷新到" + topicKey + "下");
}
}
}
}
使用refreshWithPipeline管道方法。
2.9分布式锁解决集群下的方法抢占执行:
问题描述:
启动两台heima-leadnews-schedule服务,每台服务都会去执行refresh定时任务方法
分布式锁:
控制分布式系统有序的去对共享资源进行操作,通过互斥来保证数据的一致性。
解决方案:
sexnx (SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
这种加锁的思路是,如果 key 不存在则为 key 设置 value,如果 key 已存在则 SETNX 命令不做任何操作
- 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
- 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
- 客户端A执行代码完成,删除锁
- 客户端B在等待一段时间后再去请求设置key的值,设置成功
- 客户端B执行代码完成,删除锁
/**
* 加锁
*
* @param name
* @param expire
* @return
*/
public String tryLock(String name, long expire) {
name = name + "_lock";
String token = UUID.randomUUID().toString();
RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory();
RedisConnection conn = factory.getConnection();
try {
//参考redis命令:
//set key value [EX seconds] [PX milliseconds] [NX|XX]
Boolean result = conn.set(
name.getBytes(),
token.getBytes(),
Expiration.from(expire, TimeUnit.MILLISECONDS),
RedisStringCommands.SetOption.SET_IF_ABSENT //NX
);
if (result != null && result) {
return token;
}
} finally {
RedisConnectionUtils.releaseConnection(conn, factory,false);
}
return null;
}
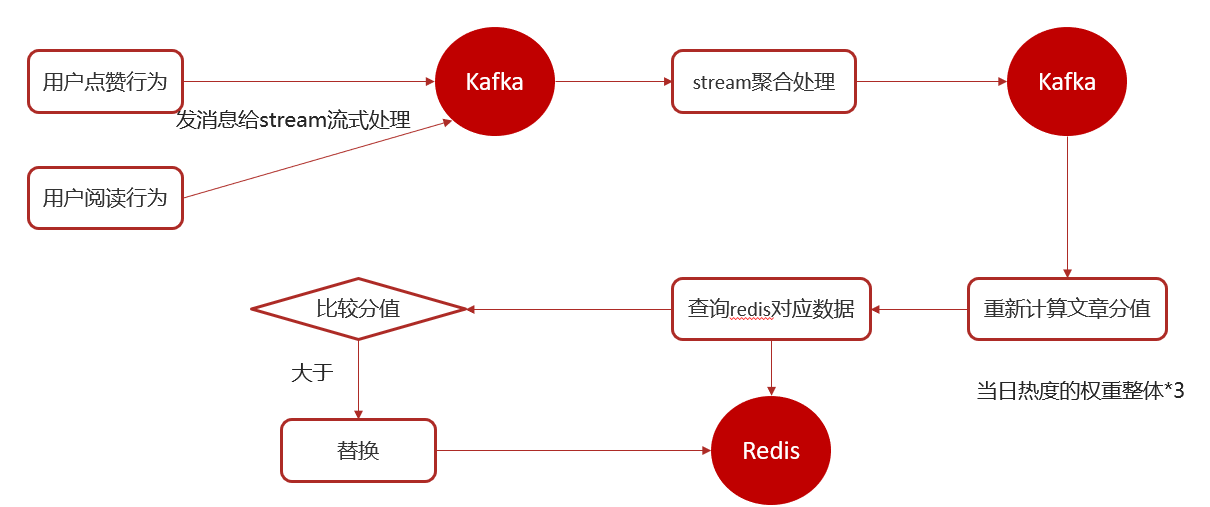
2.10热点文章实时计算:
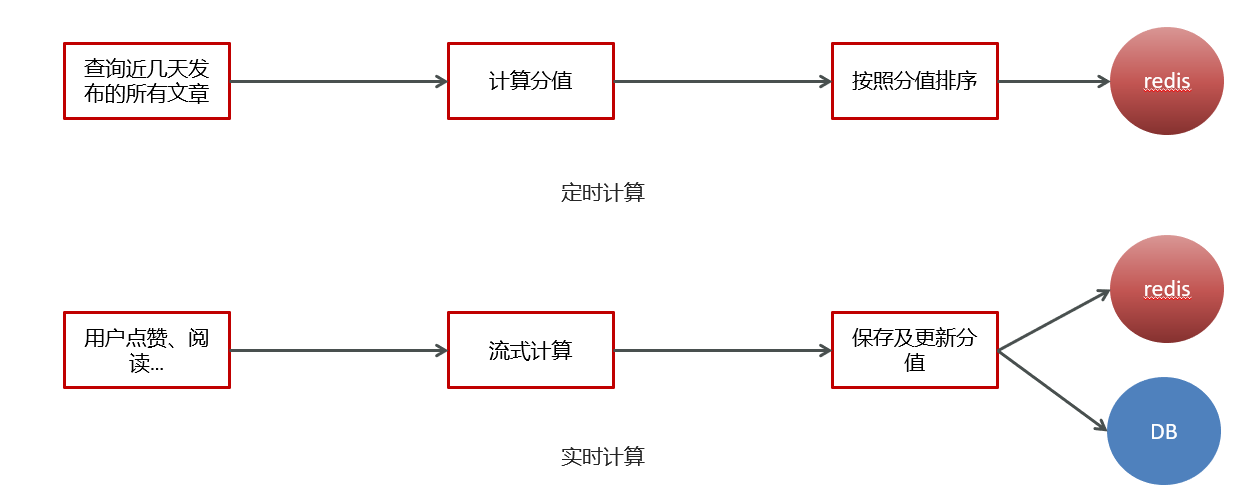
思路说明:
2.11服务降级处理
服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃
服务降级虽然会导致请求失败,但是不会导致阻塞。
实现步骤:
①:在heima-leadnews-feign-api编写降级逻辑
/**
* feign失败配置
*/
@Component
public class IArticleClientFallback implements IArticleClient {
@Override
public ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");
}
}
在自媒体微服务中添加类,扫描降级代码类的包
@Configuration
@ComponentScan("com.heima.apis.article.fallback")
public class InitConfig {
}
②:远程接口中指向降级代码
@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
public interface IArticleClient {
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto);
}
③:客户端开启降级heima-leadnews-wemedia
在wemedia的nacos配置中心里添加如下内容,开启服务降级,也可以指定服务响应的超时的时间
feign:
# 开启feign对hystrix熔断降级的支持
hystrix:
enabled: true
# 修改调用超时时间
client:
config:
default:
connectTimeout: 2000
readTimeout: 2000
openfeign的使用
IWemediaClient:
package com.xy.apis.wemedia;
import com.xy.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
@FeignClient("leadnews-wemedia")
public interface IWemediaClient {
@GetMapping("/api/v1/channel/list")
public ResponseResult getChannels();
}
WemediaClient:
package com.xy.wemedia.feign;
import com.xy.apis.wemedia.IWemediaClient;
import com.xy.model.common.dtos.ResponseResult;
import com.xy.wemedia.service.WmChannelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class WemediaClient implements IWemediaClient {
@Autowired
private WmChannelService wmChannelService;
@GetMapping("/api/v1/channel/list")
@Override
public ResponseResult getChannels() {
return wmChannelService.findAll();
}
}
IScheduleClient:
package com.xy.apis.schedule;
import com.xy.model.common.dtos.ResponseResult;
import com.xy.model.schedule.dtos.Task;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
/**
* @author 杨路恒
*/
@FeignClient("leadnews-schedule")
public interface IScheduleClient {
/**
* 添加任务
* @param task 任务对象
* @return 任务id
*/
@PostMapping("/api/v1/task/add")
public ResponseResult addTask(@RequestBody Task task);
/**
* 取消任务
* @param taskId 任务id
* @return 取消结果
*/
@GetMapping("/api/v1/task/cancel/{taskId}")
public ResponseResult cancelTask(@PathVariable("taskId") long taskId);
/**
* 按照类型和优先级来拉取任务
* @param type
* @param priority
* @return
*/
@GetMapping("/api/v1/task/pull/{type}/{priority}")
public ResponseResult pull(@PathVariable("type") int type,@PathVariable("priority") int priority);
}
ScheduleClient:
package com.xy.schedule.feign;
import com.xy.model.common.dtos.ResponseResult;
import com.xy.model.schedule.dtos.Task;
import com.xy.schedule.service.TaskService;
import com.xy.apis.schedule.IScheduleClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
/**
* @author 杨路恒
*/
@RestController
public class ScheduleClient implements IScheduleClient {
@Autowired
private TaskService taskService;
/**
* 添加任务
* @param task 任务对象
* @return
*/
@PostMapping("/api/v1/task/add")
public ResponseResult addTask(@RequestBody Task task) {
return ResponseResult.okResult(taskService.addTask(task));
}
/**
* 取消任务
* @param taskId 任务id
* @return
*/
@GetMapping("/api/v1/task/cancel/{taskId}")
public ResponseResult cancelTask(@PathVariable("taskId") long taskId) {
return ResponseResult.okResult(taskService.cancelTask(taskId));
}
/**
* 按照类型和优先级来拉取任务
* @param type
* @param priority
* @return
*/
@GetMapping("/api/v1/task/pull/{type}/{priority}")
public ResponseResult pull(@PathVariable("type") int type,@PathVariable("priority") int priority) {
return ResponseResult.okResult(taskService.pull(type,priority));
}
}
2.12素材列表查询
在自媒体引导类中天mybatis-plus的分页拦截器:
package com.xy.wemedia;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
import org.springframework.context.annotation.Bean;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
/**
* @author 杨路恒
*/
@SpringBootApplication
@EnableDiscoveryClient
@MapperScan("com.xy.wemedia.mapper")
@EnableFeignClients(basePackages = "com.xy.apis")
@EnableAsync //开启异步调用
@EnableScheduling //开启调度任务
public class WemediaApplication {
public static void main(String[] args) {
SpringApplication.run(WemediaApplication.class,args);
}
/**
* 分页拦截器
* @return
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
MyBatis Plus 是一个基于 MyBatis 的增强工具,它提供了很多方便的功能来简化数据库访问和操作。MyBatis Plus Interceptor 是 MyBatis Plus 的一个重要组件,用于在 MyBatis 执行 SQL 语句前后进行拦截和增强,实现各种功能,如分页查询、多租户支持、性能分析、乐观锁、逻辑删除等。
MyBatis Plus Interceptor 的原理如下:
- 拦截器接口:MyBatis Plus Interceptor 是一个接口,它定义了两个核心方法:
intercept和plugin。intercept方法用于实现具体的拦截逻辑。在该方法中,你可以修改 SQL 语句、参数、执行结果等。plugin方法用于告诉 MyBatis Plus 该拦截器是否要拦截某个 Statement(SQL 语句执行对象)。
- 自定义拦截器:开发者可以自定义拦截器,实现
Interceptor接口,然后将自定义的拦截器注册到 MyBatis Plus 中。 - 注册拦截器:在 MyBatis Plus 配置文件(通常是 XML 或 Java 配置类)中,你可以通过配置来注册自定义的拦截器。这样,当执行 SQL 语句时,拦截器会按照注册的顺序依次执行。
- 执行顺序:拦截器按照注册的顺序依次执行,首先执行第一个拦截器的
intercept方法,然后将结果传递给下一个拦截器,直到所有拦截器都执行完毕。这允许多个拦截器协同工作,每个拦截器可以处理不同的任务。 - 功能增强:通过拦截器,你可以实现各种功能的增强,例如:
- 分页查询:拦截查询 SQL,添加分页参数。
- 多租户支持:拦截查询 SQL,添加租户信息过滤条件。
- 性能分析:记录 SQL 执行时间等性能数据。
- 乐观锁:在更新操作前检查版本号。
- 逻辑删除:在删除操作前标记数据为已删除状态,而不是物理删除。
MyBatis Plus Interceptor 的原理是基于 Java 动态代理和反射机制实现的,它可以在 SQL 执行前后,对 SQL 语句和参数进行修改,或者对查询结果进行处理,从而实现各种功能的增强和定制。
MyBatis Plus 的分页插件是一个用于实现分页查询的重要组件,它基于 MyBatis 原生的 SQL 进行分页操作,而无需手动编写复杂的分页 SQL 语句。分页插件的原理如下:
- 分页查询条件构建:在代码中,你可以使用 MyBatis Plus 提供的
Page类来构建分页查询条件。这包括指定要查询的页码、每页记录数以及其他查询条件,例如排序条件、查询条件等。 - 分页查询拦截:当执行一个带有分页条件的查询时,MyBatis Plus 的分页插件会拦截该查询请求。这是通过 MyBatis 的拦截器机制实现的。
- SQL 重写:分页插件会在拦截的时候对原始的 SQL 语句进行重写,以包含分页逻辑。这通常涉及到以下操作:
- 将原始的查询语句包装在一个外部查询中,该外部查询会限制结果集的范围,以满足分页条件。
- 添加
LIMIT或OFFSET子句(具体取决于数据库的支持情况)来限制结果集的大小和偏移量。 - 修改查询语句中的排序条件,以确保结果的顺序正确。
- SQL 参数处理:分页插件还会根据分页条件中的页码和每页记录数,计算出适当的偏移量和限制值,并将它们添加到 SQL 语句中。这确保了只返回分页查询条件指定的结果子集。
- 执行查询:经过 SQL 重写和参数处理后,MyBatis 执行修改后的 SQL 语句,从数据库中检索出分页结果集。
- 结果封装:查询结果被封装到一个
Page对象中,该对象包括了查询的结果列表以及有关分页信息的元数据,如总记录数、总页数、当前页码等。 - 返回结果:分页查询的结果
Page对象被返回给调用方,允许应用程序访问和操作分页数据。
总的来说,MyBatis Plus 分页插件的原理是在查询前拦截查询请求,重写 SQL 语句以包含分页逻辑,执行查询,将结果封装到一个 Page 对象中,最终返回给调用方。
2.13分布式id
随着业务的增长,文章表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。
文章端相关的表都使用雪花算法生成id,包括ap_article、 ap_article_config、 ap_article_content
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
第一:在实体类中的id上加入如下配置,指定类型为id_worker
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
第二:在application.yml文件中配置数据中心id和机器id
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.article.pojos
global-config:
datacenter-id: 1
workerId: 1
datacenter-id:数据中心id(取值范围:0-31)
workerId:机器id(取值范围:0-31)
2.14自媒体文章上下架
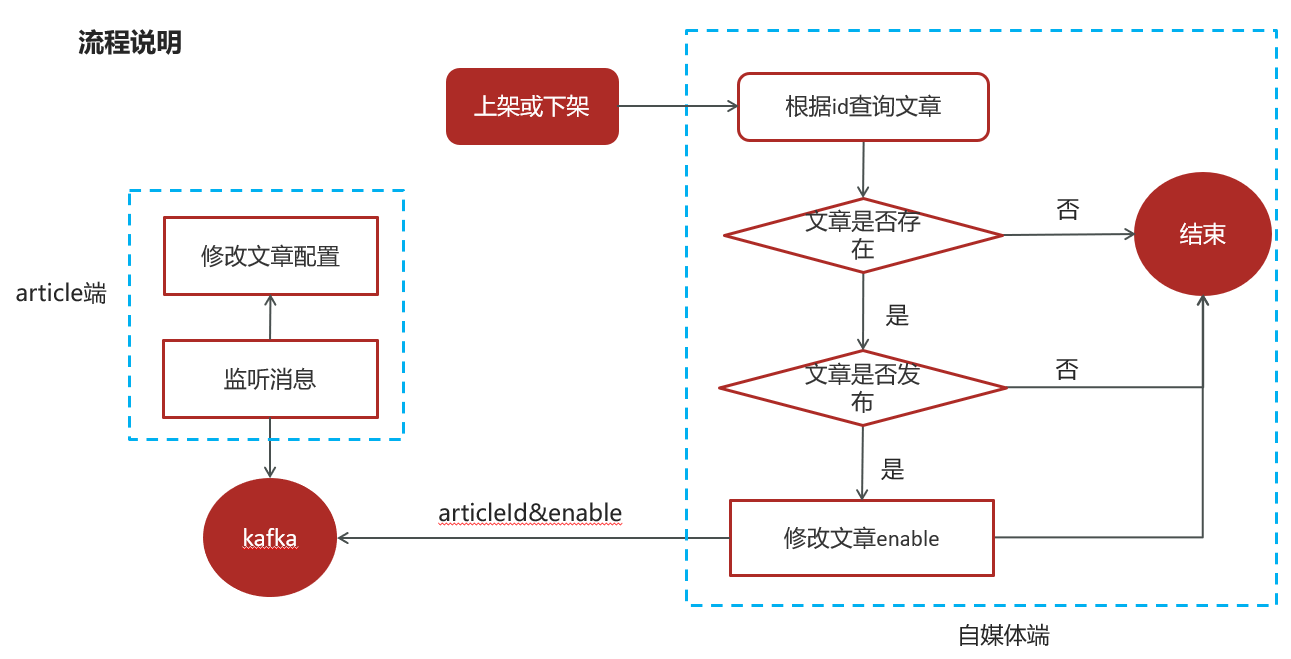
自媒体微服务发送消息,WmNewsServiceImpl:
public ResponseResult downOrUp(WmNewsDto wmNewsDto) {
//1.检查参数
if (wmNewsDto.getId() == null){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.查询文章
WmNews wmNews = getById(wmNewsDto.getId());
if (wmNews == null){
return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"文章不存在");
}
//3.判断文章是否已发布
if (!wmNews.getStatus().equals(WmNews.Status.PUBLISHED.getCode())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"当前文章不是发布状态,不能上下架");
}
//4.修改文章enable
if (wmNewsDto != null && wmNewsDto.getEnable() > -1 && wmNewsDto.getEnable() < 2){
update(Wrappers.<WmNews>lambdaUpdate().set(WmNews::getEnable,wmNewsDto.getEnable()).eq(WmNews::getId,wmNews.getId()));
//发送消息,通知article端修改文章配置
if (wmNews.getArticleId() != null){
Map<String,Object> map = new HashMap<>();
map.put("articleId",wmNews.getArticleId());
map.put("enable",wmNews.getEnable());
kafkaTemplate.send(WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC,JSON.toJSONString(map));
}
}
return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}
在article端编写监听,接收数据, ArticleIsDownListener:
package com.xy.article.listener;
import com.alibaba.fastjson.JSON;
import com.xy.common.constants.WmNewsMessageConstants;
import com.xy.article.service.ApArticleConfigService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Map;
/**
* @author 杨路恒
*/
@Component
@Slf4j
public class ArticleIsDownListener {
@Autowired
private ApArticleConfigService apArticleConfigService;
@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)
public void onMessage(String message) {
if (StringUtils.isNoneBlank(message)){
Map map = JSON.parseObject(message, Map.class);
apArticleConfigService.updateByMap(map);
log.info("article端文章配置修改,articleId={}",map.get("articleId"));
}
}
}
2.15es文章自动审核完成构建索引
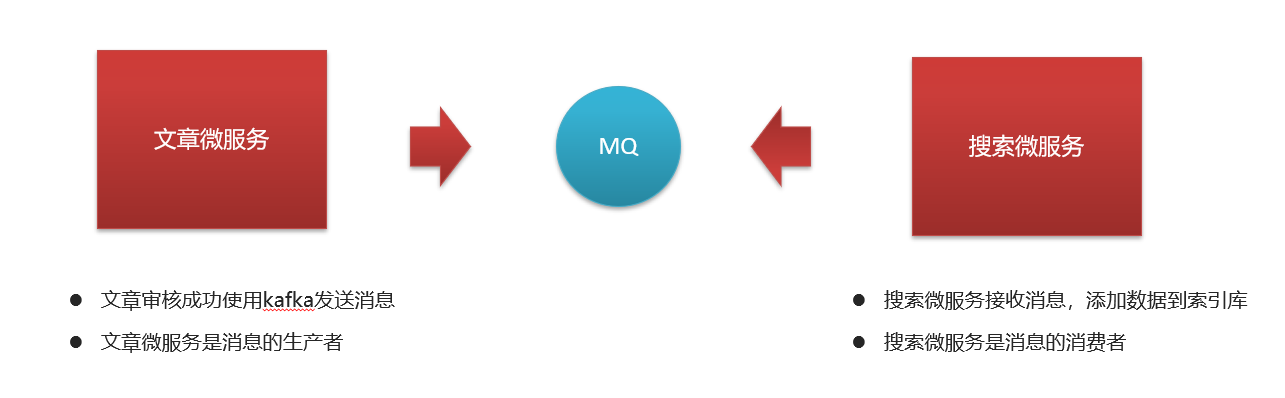
文章微服务发送消息, ArticleFreemarkerServiceImpl:
private void createArticleESIndex(ApArticle apArticle, String content, String path) {
SearchArticleVo vo = new SearchArticleVo();
BeanUtils.copyProperties(apArticle,vo);
vo.setContent(content);
vo.setStaticUrl(path);
kafkaTemplate.send(ArticleConstants.ARTICLE_ES_SYNC_TOPIC, JSON.toJSONString(vo));
}
搜索微服务接收消息并创建索引, SyncArticleListener:
package com.xy.search.listener;
import com.alibaba.fastjson.JSON;
import com.xy.common.constants.ArticleConstants;
import com.xy.model.search.vos.SearchArticleVo;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.io.IOException;
/**
* @author 杨路恒
*/
@Component
@Slf4j
public class SyncArticleListener {
@Autowired
private RestHighLevelClient restHighLevelClient;
@KafkaListener(topics = ArticleConstants.ARTICLE_ES_SYNC_TOPIC)
public void onMessage(String message){
if(StringUtils.isNotBlank(message)){
log.info("SyncArticleListener,message={}",message);
SearchArticleVo searchArticleVo = JSON.parseObject(message, SearchArticleVo.class);
IndexRequest indexRequest = new IndexRequest("app_info_article");
indexRequest.id(searchArticleVo.getId().toString());
indexRequest.source(message, XContentType.JSON);
try {
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
log.error("sync es error={}",e);
}
}
}
}
2.16xxljob热点文章定时任务
实现思路:
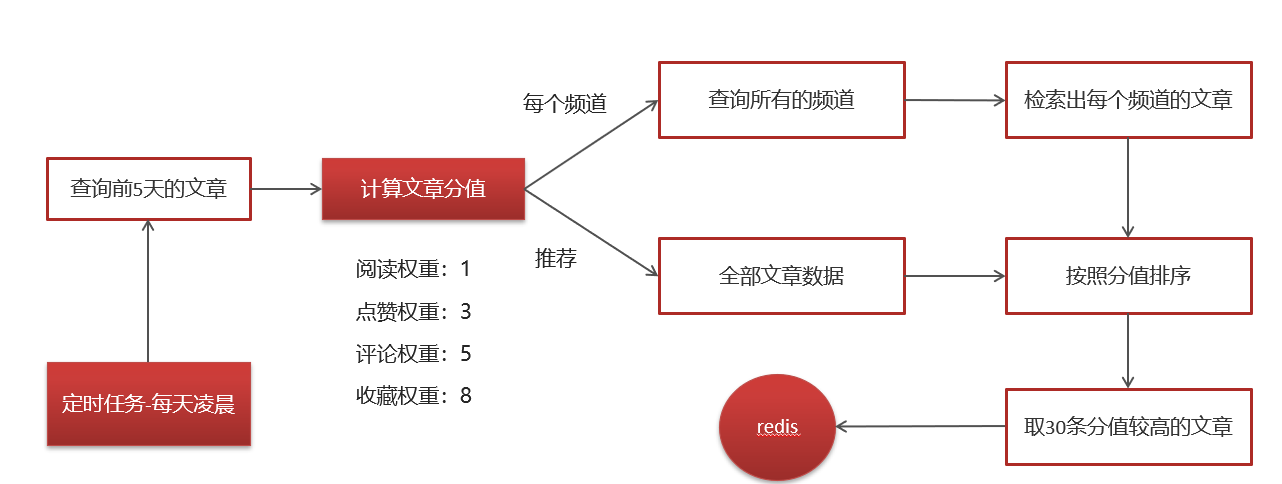
频道列表远程接口准备:
计算完成新热数据后,需要给每个频道缓存一份数据,所以需要查询所有频道信息。
IWemediaClient:
package com.xy.article.service;
/**
* @author 杨路恒
*/
public interface HotArticleService {
/**
* 计算热点文章
*/
public void computeHotArticle();
}
WemediaClient:
package com.xy.wemedia.feign;
import com.xy.apis.wemedia.IWemediaClient;
import com.xy.model.common.dtos.ResponseResult;
import com.xy.wemedia.service.WmChannelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class WemediaClient implements IWemediaClient {
@Autowired
private WmChannelService wmChannelService;
@GetMapping("/api/v1/channel/list")
@Override
public ResponseResult getChannels() {
return wmChannelService.findAll();
}
}
定义业务层接口,在article微服务中新建任务类:
ComputeHotArticleJob:
package com.xy.article.job;
import com.xy.article.service.HotArticleService;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* @author 杨路恒
*/
@Component
@Slf4j
public class ComputeHotArticleJob {
@Autowired
private HotArticleService hotArticleService;
@XxlJob("computeHotArticleJob")
public void handle(){
log.info("热文章分值计算调度任务开始执行...");
hotArticleService.computeHotArticle();
log.info("热文章分值计算调度任务结束...");
}
}
HotArticleServiceImpl:
package com.xy.article.service.impl;
import com.alibaba.fastjson.JSON;
import com.xy.common.constants.ArticleConstants;
import com.xy.common.redis.CacheService;
import com.xy.model.article.pojos.ApArticle;
import com.xy.model.article.vos.HotArticleVo;
import com.xy.model.common.dtos.ResponseResult;
import com.xy.model.wemedia.pojos.WmChannel;
import com.xy.apis.wemedia.IWemediaClient;
import com.xy.article.mapper.ApArticleMapper;
import com.xy.article.service.HotArticleService;
import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author 杨路恒
*/
@Service
@Transactional
@Slf4j
public class HotArticleServiceImpl implements HotArticleService {
@Autowired
private ApArticleMapper apArticleMapper;
/**
* 计算热点文章
*/
@Override
public void computeHotArticle() {
//1.查询前5天的文章数据
Date date = DateTime.now().minusDays(50).toDate();
List<ApArticle> articleListByLast5days = apArticleMapper.findArticleListByLast5days(date);
//2.计算文章的分值
List<HotArticleVo> hotArticleVoList = computeHotArticle(articleListByLast5days);
//3.为每个频道缓存30条分值较高的文章
cacheTagToRedis(hotArticleVoList);
}
@Autowired
private IWemediaClient iWemediaClient;
@Autowired
private CacheService cacheService;
/**
* 为每个频道缓存30条分值较高的文章
* @param hotArticleVoList
*/
private void cacheTagToRedis(List<HotArticleVo> hotArticleVoList) {
//为每个频道缓存30条分值较高的文章
ResponseResult responseResult = iWemediaClient.getChannels();
if (responseResult.getCode().equals(200)){
String jsonString = JSON.toJSONString(responseResult.getData());
List<WmChannel> wmChannels = JSON.parseArray(jsonString, WmChannel.class);
//检索出每个频道的文章
if (wmChannels != null && wmChannels.size() > 0){
for (WmChannel wmChannel : wmChannels) {
List<HotArticleVo> hotArticleVos = hotArticleVoList.stream().filter(x -> x.getChannelId().equals(wmChannel.getId())).collect(Collectors.toList());
//给文章进行排序,取30条分值较高的文章存入redis key:频道id value:30条分值较高的文章
sortAndCache(hotArticleVos, ArticleConstants.HOT_ARTICLE_FIRST_PAGE + wmChannel.getId());
}
}
}
//设置推荐数据
//给文章进行排序,取30条分值较高的文章存入redis key:频道id value:30条分值较高的文章
sortAndCache(hotArticleVoList,ArticleConstants.HOT_ARTICLE_FIRST_PAGE + ArticleConstants.DEFAULT_TAG);
}
/**
* 排序并且缓存数据
* @param hotArticleVos
* @param s
*/
private void sortAndCache(List<HotArticleVo> hotArticleVos, String s) {
hotArticleVos = hotArticleVos.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());
if (hotArticleVos.size() > 30) {
hotArticleVos = hotArticleVos.subList(0,30);
}
cacheService.set(s,JSON.toJSONString(hotArticleVos));
}
/**
* 计算文章分值
* @param articleListByLast5days
* @return
*/
private List<HotArticleVo> computeHotArticle(List<ApArticle> articleListByLast5days) {
List<HotArticleVo> hotArticleVoList = new ArrayList<>();
if (articleListByLast5days != null && articleListByLast5days.size() > 0) {
for (ApArticle apArticle : articleListByLast5days) {
HotArticleVo hotArticleVo = new HotArticleVo();
BeanUtils.copyProperties(apArticle,hotArticleVo);
Integer score = computeScore(apArticle);
hotArticleVo.setScore(score);
hotArticleVoList.add(hotArticleVo);
}
}
return hotArticleVoList;
}
/**
* 计算文章的具体分值
* @param apArticle
* @return
*/
private Integer computeScore(ApArticle apArticle) {
Integer score = 0;
if (apArticle.getLikes() != null){
score += apArticle.getLikes() + ArticleConstants.HOT_ARTICLE_LIKE_WEIGHT;
}
if (apArticle.getViews() != null){
score += apArticle.getViews();
}
if (apArticle.getComment() != null){
score += apArticle.getComment() + ArticleConstants.HOT_ARTICLE_COMMENT_WEIGHT;
}
if (apArticle.getCollection() != null){
score += apArticle.getCollection() + ArticleConstants.HOT_ARTICLE_COLLECTION_WEIGHT;
}
return score;
}
}
待优化:
使用FastDFS作为静态资源存储器,在其上实现热静态资源缓存、淘汰等功能(待优化)
运用Hbase技术,存储系统中的冷数据,保证系统数据的可靠性(待优化)
运用ES搜索技术,对冷数据、文章数据建立索引,以保证冷数据、文章查询性能(待优化)
当用户 Logout 的话,JWT 也还有效。除非,我们在后端增加额外的处理逻辑比如将失效的 JWT 存储起来,后端先验证 JWT 是否有效再进行处理。
3.QPS估算方法、性能测试:
QPS(Query Per Second):每秒请求数,就是说服务器在一秒的时间内处理了多少个请求。
怎么估出每秒钟能处理多少请求呢?
方式一:自己在接口里记录
这种方式指的是在你的接口里,日志记录了能体现该接口特性的,并具有唯一性的字符串!
例如,下面这一段代码:
@RestController
@RequestMapping("/home")
public class IndexController {
//省略
@RequestMapping("/index")
String index() {
logger.info("渣渣烟");
return "index";
}
}
假设现在我要统计index这个接口的QPS!
OK,什么叫能体现该接口特性的字符串呢!就像上面的"渣渣烟"这个字符串,只在index这个接口里出现过,没在其他其他接口里出现过!因此,只要统计出"渣渣烟"这个字符串在日志里的出现次数,就能知道该接口的请求次数!
什么叫具有唯一性的字符串呢!所谓唯一性,指的是"渣渣烟"这个字符串,在这个接口的一次调用流程中,只出现一次!如果出现两次,就会导致到时候统计出来的次数会多一倍,所以尽量选择具有唯一性的字段!
方式二:利用tomcat的access log
tomcat自带的access log功能:
server.tomcat.accesslog.directory
设定log的目录,默认: logs
server.tomcat.accesslog.enabled
是否开启access log,默认: false
此时,你访问一次/home/index地址,会有下面这样日志:
127.0.0.1 - - [xxx] "POST /home/index HTTP/1.1" 200 138
执行一串命令:
cat xx.log |grep 'GET /mvc2'|cut -d ' ' -f4|uniq -c|sort -n -r
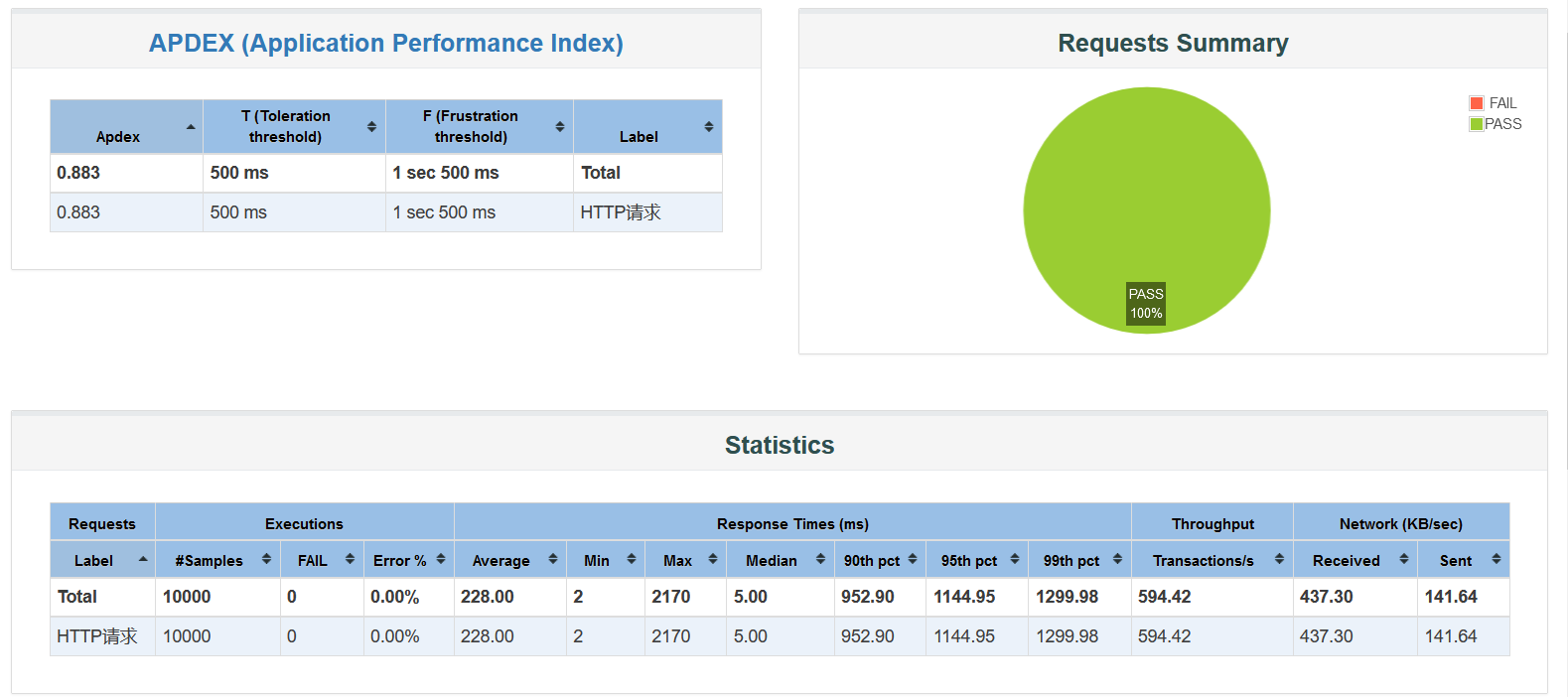
JMeter测试:
自我介绍:
面试官,您好,首先很感谢您给我的面试机会!我叫杨路恒,今年24岁,山东济宁人,就读于陕西师范大学,今年研二,软件工程专业,研究方向为知识图谱。大学时间我主要利用课外时间学习了 Java 以及 一些框架 。在校期间参与了全国大学生数学建模竞赛和全国大学生英语竞赛,并且在数学建模比赛中担任队长并获得了陕西省一等奖。说到业余爱好的话,一个是比较喜欢通过博客整理分享自己所学知识,现在在CSDN上的粉丝数达到了3k+,访问量达到了44W+。 另一个是喜欢旅游和骑行的方式来放松。这就是我的自我介绍,感谢。