四、Map
1.HashMap
HashMap实现了Map接口,可以方便地按照键存取值,内部使用数组链表和哈希的方式进行实现,这决定了它有如下特点:
- 根据键保存和获取值的效率都很高,为O(1),每个单向链表往往只有一个或少数几个节点,根据hash值就可以直接快速定位;
- HashMap中的键值对没有顺序,因为hash值是随机的。
需要说明的是,HashMap不是线程安全的,Java中还有一个类Hashtable,它是Java最早实现的容器类之一,实现了Map接口,实现原理与HashMap类似,但没有特别的优化,它内部通过synchronized实现了线程安全。
在HashMap中,键和值都可以为null,而在Hashtable中不可以。在不需要并发安全的场景中,推荐使用HashMap。在高并发的场景中,推荐使用ConcurrentHashMap。
1.1HashMap的容量、扩容
先来看一下,HashMap中都定义了哪些成员变量。
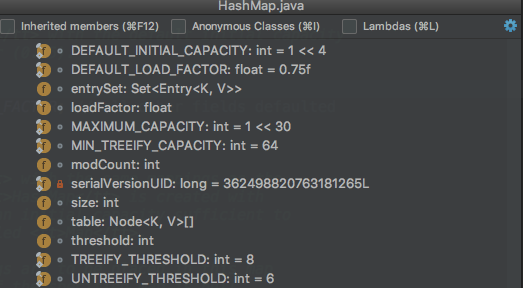
上面是一张HashMap中主要的成员变量的图,其中有一个是我们本文主要关注的: size、loadFactor、threshold、DEFAULT_LOAD_FACTOR和DEFAULT_INITIAL_CAPACITY。
我们先来简单解释一下这些参数的含义,然后再分析他们的作用。
HashMap类中有以下主要成员变量:
- transient int size;
- 记录了Map中KV对的个数
- loadFactor
- 装载因子,用来衡量HashMap满的程度。loadFactor的默认值为0.75f(
static final float DEFAULT_LOAD_FACTOR = 0.75f;)。
- 装载因子,用来衡量HashMap满的程度。loadFactor的默认值为0.75f(
- int threshold;
- 临界值,当实际KV个数超过threshold时,HashMap会将容量扩容,threshold=容量*装载因子
- 除了以上这些重要成员变量外,HashMap中还有一个和他们紧密相关的概念:capacity
- 容量,如果不指定,默认容量是16(
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;)
- 容量,如果不指定,默认容量是16(
可能看完了你还是有点蒙,size和capacity之间有啥关系?为啥要定义这两个变量。loadFactor和threshold又是干啥的?
1.1.1size 和 capacity
HashMap中的size和capacity之间的区别其实解释起来也挺简单的。我们知道,HashMap就像一个“桶”,那么capacity就是这个桶“当前”最多可以装多少元素,而size表示这个桶已经装了多少元素。来看下以下代码:
Map<String, String> map = new HashMap<String, String>();
map.put("hollis", "hollischuang");
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size : " + size.get(map));
我们定义了一个新的HashMap,并想其中put了一个元素,然后通过反射的方式打印capacity和size。输出结果为:
capacity : 16、size : 1
默认情况下,一个HashMap的容量(capacity)是16,设计成16的好处主要是可以使用按位与替代取模来提升hash的效率。
我们知道,HashMap的重载的构造函数中,有一个是支持传入initialCapacity的,那么我们尝试着设置一下,看结果如何。
Map<String, String> map = new HashMap<String, String>(1);
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Map<String, String> map = new HashMap<String, String>(7);
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Map<String, String> map = new HashMap<String, String>(9);
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
分别执行以上3段代码,分别输出:capacity : 1、capacity : 8、capacity : 16。
也就是说,默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(1->1、7->8、9->16)
相关信息
这里有一个小建议:在初始化HashMap的时候,应该尽量指定其大小。尤其是当你已知map中存放的元素个数时。(《阿里巴巴Java开发规约》)
1.1.2loadFactor 和 threshold
前面我们提到过,HashMap有扩容机制,就是当达到扩容条件时会进行扩容,从16扩容到32、64、128...
那么,这个扩容条件指的是什么呢?
其实,HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在HashMap中,threshold = loadFactor * capacity。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
对于一个默认的HashMap来说,默认情况下,当其size大于12(16*0.75)时就会触发扩容。
验证代码如下:
Map<String, String> map = new HashMap<>();
map.put("hollis1", "hollischuang");
map.put("hollis2", "hollischuang");
map.put("hollis3", "hollischuang");
map.put("hollis4", "hollischuang");
map.put("hollis5", "hollischuang");
map.put("hollis6", "hollischuang");
map.put("hollis7", "hollischuang");
map.put("hollis8", "hollischuang");
map.put("hollis9", "hollischuang");
map.put("hollis10", "hollischuang");
map.put("hollis11", "hollischuang");
map.put("hollis12", "hollischuang");
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size : " + size.get(map));
Field threshold = mapType.getDeclaredField("threshold");
threshold.setAccessible(true);
System.out.println("threshold : " + threshold.get(map));
Field loadFactor = mapType.getDeclaredField("loadFactor");
loadFactor.setAccessible(true);
System.out.println("loadFactor : " + loadFactor.get(map));
map.put("hollis13", "hollischuang");
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size : " + size.get(map));
Field threshold = mapType.getDeclaredField("threshold");
threshold.setAccessible(true);
System.out.println("threshold : " + threshold.get(map));
Field loadFactor = mapType.getDeclaredField("loadFactor");
loadFactor.setAccessible(true);
System.out.println("loadFactor : " + loadFactor.get(map));
输出结果:
capacity : 16
size : 12
threshold : 12
loadFactor : 0.75
capacity : 32
size : 13
threshold : 24
loadFactor : 0.75
当HashMap中的元素个数达到13的时候,capacity就从16扩容到32了。
相关信息
HashMap中还提供了一个支持传入initialCapacity,loadFactor两个参数的方法,来初始化容量和装载因子。不过,一般不建议修改loadFactor的值。
1.1.3总结
HashMap中size表示当前共有多少个KV对,capacity表示当前HashMap的容量是多少,默认值是16,每次扩容都是成倍的。loadFactor是装载因子,当Map中元素个数超过loadFactor* capacity的值时,会触发扩容。loadFactor* capacity可以用threshold表示。
注意:文中分析基于JDK1.8.0_73
1.2HashMap中hash方法的原理
1.2.1HashMap 的数据结构
在Java中,保存数据有两种比较简单的数据结构:数组和链表。**数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。**上面我们提到过,常用的哈希函数的冲突解决办法中有一种方法叫做链地址法,其实就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。
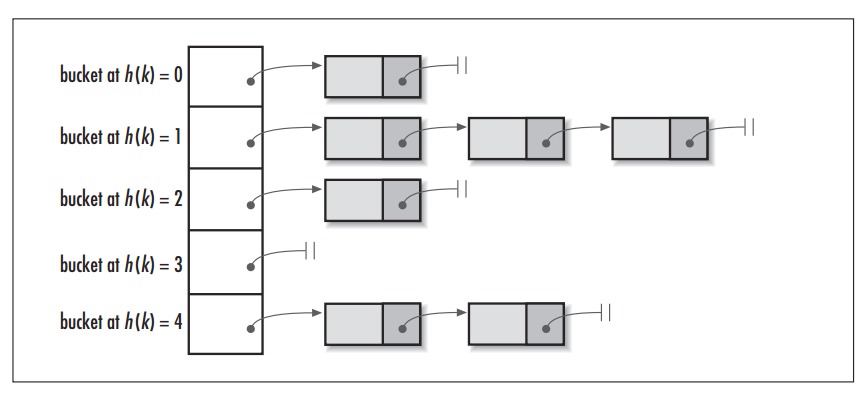
我们可以从上图看到,左边很明显是个数组,数组的每个成员是一个链表。该数据结构所容纳的所有元素均包含一个指针,用于元素间的链接。我们根据元素的自身特征把元素分配到不同的链表中去,反过来我们也正是通过这些特征找到正确的链表,再从链表中找出正确的元素。其中,根据元素特征计算元素数组下标的方法就是哈希算法,即本文的主角hash()函数(当然,还包括indexOf()函数)。
1.2.2hash方法
我们拿JDK 1.7的HashMap为例,其中定义了一个final int hash(Object k) 方法,其主要被以下方法引用。
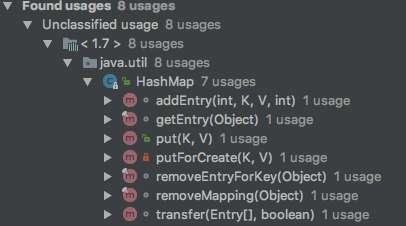
上面的方法主要都是增加和删除方法,这不难理解,当我们要对一个链表数组中的某个元素进行增删的时候,首先要知道他应该保存在这个链表数组中的哪个位置,即他在这个数组中的下标。而hash()方法的功能就是根据Key来定位其在HashMap中的位置。HashTable、ConcurrentHashMap同理。
首先,在同一个版本的Jdk中,HashMap、HashTable以及ConcurrentHashMap里面的hash方法的实现是不同的。在不同的版本的JDK中(Java7 和 Java8)中也是有区别的。我会尽量全部介绍到。相信,看完这篇文章,你会彻底理解hash方法。
在上代码之前,我们先来做个简单分析。我们知道,hash方法的功能是根据Key来定位这个K-V在链表数组中的位置的。也就是hash方法的输入应该是个Object类型的Key,输出应该是个int类型的数组下标。如果让你设计这个方法,你会怎么做?
其实简单,我们只要调用Object对象的hashCode()方法,该方法会返回一个整数,然后用这个数对HashMap或者HashTable的容量进行取模就行了。没错,其实基本原理就是这个,只不过,在具体实现上,由两个方法int hash(Object k)和int indexFor(int h, int length)来实现。但是考虑到效率等问题,HashMap的实现会稍微复杂一点。
相关信息
hash :该方法主要是将Object转换成一个整型。
indexFor :该方法主要是将hash生成的整型转换成链表数组中的下标。
HashMap In Java 7:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
前面我说过,indexFor方法其实主要是将hash生成的整型转换成链表数组中的下标。那么return h & (length-1);是什么意思呢?其实,他就是取模。Java之所以使用位运算(&)来代替取模运算(%),最主要的考虑就是效率。位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
那么,为什么可以使用位运算(&)来实现取模运算(%)呢?这实现的原理如下:
相关信息
X % 2^n = X & (2^n - 1)
2n表示2的n次方,也就是说,一个数对2n取模 == 一个数和(2^n - 1)做按位与运算 。
假设n为3,则2^3 = 8,表示成2进制就是1000。2^3 -1 = 7 ,即0111。
此时X & (2^3 - 1) 就相当于取X的2进制的最后三位数。
从2进制角度来看,X / 8相当于 X >> 3,即把X右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了。或者你可以找几个例子试一下。
相关信息
6 % 8 = 6 ,6 & 7 = 6
10 & 8 = 2 ,10 & 7 = 2
所以,return h & (length-1);只要保证length的长度是2^n的话,就可以实现取模运算了。而HashMap中的length也确实是2的倍数,初始值是16,之后每次扩充为原来的2倍。
分析完indexFor方法后,我们接下来准备分析hash方法的具体原理和实现。在深入分析之前,至此,先做个总结。
HashMap的数据是存储在链表数组里面的。在对HashMap进行插入/删除等操作时,都需要根据K-V对的键值定位到他应该保存在数组的哪个下标中。而这个通过键值求取下标的操作就叫做哈希。HashMap的数组是有长度的,Java中规定这个长度只能是2的倍数,初始值为16。简单的做法是先求取出键值的hashcode,然后在将hashcode得到的int值对数组长度进行取模。为了考虑性能,Java总采用按位与操作实现取模操作。
接下来我们会发现,无论是用取模运算还是位运算都无法直接解决冲突较大的问题。比如:CA11 0000和0001 0000在对0000 1111进行按位与运算后的值是相等的。
两个不同的键值,在对数组长度进行按位与运算后得到的结果相同,这不就发生了冲突吗。那么如何解决这种冲突呢,来看下Java是如何做的。
其中的主要代码部分如下:
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
这段代码是为了对key的hashCode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率,也就是说,尽量做到任何一位的变化都能对最终得到的结果产生影响。
举个例子来说,我们现在想向一个HashMap中put一个K-V对,Key的值为“hollischuang”,经过简单的获取hashcode后,得到的值为“1011000110101110011111010011011”,如果当前HashTable的大小为16,即在不进行扰动计算的情况下,他最终得到的index结果值为11。由于15的二进制扩展到32位为“00000000000000000000000000001111”,所以,一个数字在和他进行按位与操作的时候,前28位无论是什么,计算结果都一样(因为0和任何数做与,结果都为0)。如下图所示。
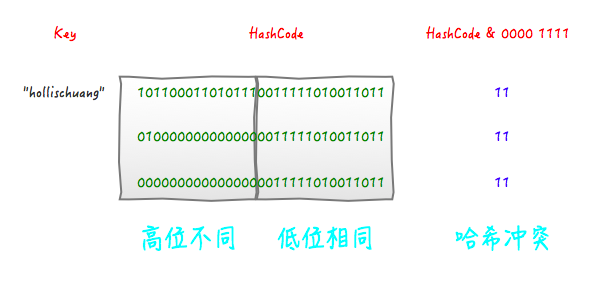
可以看到,后面的两个hashcode经过位运算之后得到的值也是11 ,虽然我们不知道哪个key的hashcode是上面例子中的那两个,但是肯定存在这样的key,这就产生了冲突。
那么,接下来,我看看一下经过扰动的算法最终的计算结果会如何。

从上面图中可以看到,之前会产生冲突的两个hashcode,经过扰动计算之后,最终得到的index的值不一样了,这就很好的避免了冲突。
相关信息
其实,使用位运算代替取模运算,除了性能之外,还有一个好处就是可以很好的解决负数的问题。因为我们知道,hashcode的结果是int类型,而int的取值范围是-2^31 ~ 2^31 - 1,即[ -2147483648, 2147483647];这里面是包含负数的,我们知道,对于一个负数取模还是有些麻烦的。如果使用二进制的位运算的话就可以很好的避免这个问题。首先,不管hashcode的值是正数还是负数。length-1这个值一定是个正数。那么,他的二进制的第一位一定是0(有符号数用最高位作为符号位,“0”代表“+”,“1”代表“-”),这样里两个数做按位与运算之后,第一位一定是个0,也就是,得到的结果一定是个正数。
HashTable In Java 7:
上面是Java 7中HashMap的hash方法以及indexOf方法的实现,那么接下来我们要看下,线程安全的HashTable是如何实现的,和HashMap有何不同,并试着分析下不同的原因。以下是Java 7中HashTable的hash方法的实现。
private int hash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();
}
我们可以发现,很简单,相当于只是对k做了个简单的hash,取了一下其hashCode。而HashTable中也没有indexOf方法,取而代之的是这段代码:int index = (hash & 0x7FFFFFFF) % tab.length;。也就是说,HashMap和HashTable对于计算数组下标这件事,采用了两种方法。HashMap采用的是位运算,而HashTable采用的是直接取模。
我们前面说过,HashMap之所以不用取模的原因是为了提高效率。有人认为,因为HashTable是个线程安全的类,本来就慢,所以Java并没有考虑效率问题,就直接使用取模算法了呢?但是其实并不完全是,Java这样设计还是有一定的考虑在的,虽然这样效率确实是会比HashMap慢一些。
其实,HashTable采用简单的取模是有一定的考虑在的。这就要涉及到HashTable的构造函数和扩容函数了。由于篇幅有限,这里就不贴代码了,直接给出结论:
相关信息
HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。
也就是说,HashTable的链表数组的默认大小是一个素数、奇数。之后的每次扩充结果也都是奇数。
由于HashTable会尽量使用素数、奇数作为容量的大小。当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀。(这个是可以证明出来的,由于不是本文重点,暂不详细介绍,可参考:http://zhaox.github.io/algorithm/2015/06/29/hash
至此,我们看完了Java 7中HashMap和HashTable中对于hash的实现,我们来做个简单的总结。
- HashMap默认的初始化大小为16,之后每次扩充为原来的2倍。
- HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。
- 当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀,所以单从这一点上看,HashTable的哈希表大小选择,似乎更高明些。因为hash结果越分散效果越好。
- 在取模计算时,如果模数是2的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。所以从hash计算的效率上,又是HashMap更胜一筹。
- 但是,HashMap为了提高效率使用位运算代替哈希,这又引入了哈希分布不均匀的问题,所以HashMap为解决这问题,又对hash算法做了一些改进,进行了扰动计算。
ConcurrentHashMap In Java 7:
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
int j = (hash >>> segmentShift) & segmentMask;
上面这段关于ConcurrentHashMap的hash实现其实和HashMap如出一辙。都是通过位运算代替取模,然后再对hashcode进行扰动。区别在于,ConcurrentHashMap 使用了一种变种的Wang/Jenkins 哈希算法,其主要目的也是为了把高位和低位组合在一起,避免发生冲突。至于为啥不和HashMap采用同样的算法进行扰动,我猜这只是程序员自由意志的选择吧。至少我目前没有办法证明哪个更优。
HashMap In Java 8:
在Java 8 之前,HashMap和其他基于map的类都是通过链地址法解决冲突,它们使用单向链表来存储相同索引值的元素。在最坏的情况下,这种方式会将HashMap的get方法的性能从O(1)降低到O(n)。为了解决在频繁冲突时hashmap性能降低的问题,Java 8中使用平衡树来替代链表存储冲突的元素。这意味着我们可以将最坏情况下的性能从O(n)提高到O(logn)。关于HashMap在Java 8中的优化,我后面会有文章继续深入介绍。
如果恶意程序知道我们用的是Hash算法,则在纯链表情况下,它能够发送大量请求导致哈希碰撞,然后不停访问这些key导致HashMap忙于进行线性查找,最终陷入瘫痪,即形成了拒绝服务攻击(DoS)。
关于Java 8中的hash函数,原理和Java 7中基本类似。Java 8中这一步做了优化,只做一次16位右位移异或混合,而不是四次,但原理是不变的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的。以上方法得到的int的hash值,然后再通过h & (table.length -1)来得到该对象在数据中保存的位置。
HashTable In Java 8:
在Java 8的HashTable中,已经不再有hash方法了。但是哈希的操作还是在的,比如在put方法中就有如下实现:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
这其实和Java 7中的实现几乎无差别,就不做过多的介绍了。
ConcurrentHashMap In Java 8:
Java 8 里面的求hash的方法从hash改为了spread。实现方式如下:
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)。
1.2.3总结
至此,我们已经分析完了HashMap、HashTable以及ConcurrentHashMap分别在Jdk 1.7 和 Jdk 1.8中的实现。我们可以发现,为了保证哈希的结果可以分散、为了提高哈希的效率,JDK在一个小小的hash方法上就有很多考虑,做了很多事情。当然,我希望我们不仅可以深入了解背后的原理,还要学会这种对代码精益求精的态度。
Jdk的源代码,每一行都很有意思,都值得花时间去钻研、推敲。
参考:https://hollischuang.gitee.io/tobetopjavaer/#/basics/java-basic/hash-in-hashmap
2.TreeMap
TreeMap与HashMap相比,TreeMap同样实现了Map接口,但内部使用红黑树实现。红黑树是统计效率比较高的大致平衡的排序二叉树,这决定了它有如下特点:
按键有序,TreeMap同样实现了SortedMap和NavigableMap接口,可以方便地根据键的顺序进行查找,如第一个、最后一个、某一范围的键、邻近键等。
为了按键有序,TreeMap要求键实现Comparable接口或通过构造方法提供一个Comparator对象。
根据键保存、查找、删除的效率比较高,为O(h), h为树的高度,在树平衡的情况下,h为log2(N), N为节点数。
HashMap还是TreeMap呢:不要求排序,优先考虑HashMap,要求排序,考虑TreeMap。
3.LinkedHashMap
LinkedHashMap可以保持插入顺序或访问顺序。插入顺序经常用于处理键值对的数据,并保持其输入顺序,也经常用于键已经排好序的场景,相比TreeMap效率更高;访问顺序经常用于实现LRU缓存。实现原理上,它是HashMap的子类,但内部有一个双向链表以维护节点的顺序。